Learning to Interactively
Learn and Assist
Abstract
When deploying autonomous agents in the real world, we need effective ways of communicating objectives to them. Traditional skill learning has revolved around reinforcement and imitation learning, each with rigid constraints on the format of information exchanged between the human and the agent. While scalar rewards carry little information, demonstrations require significant effort to provide and may carry more information than is necessary. Furthermore, rewards and demonstrations are often defined and collected before training begins, when the human is most uncertain about what information would help the agent. In contrast, when humans communicate objectives with each other, they make use of a large vocabulary of informative behaviors, including non-verbal communication, and often communicate throughout learning, responding to observed behavior. In this way, humans communicate intent with minimal effort. In this paper, we propose such interactive learning as an alternative to reward or demonstration-driven learning. To accomplish this, we introduce a multi-agent training framework that enables an agent to learn from another agent who knows the current task. Through a series of experiments, we demonstrate the emergence of a variety of interactive learning behaviors, including information-sharing, information-seeking, and question-answering. Most importantly, we find that our approach produces an agent that is capable of learning interactively from a human user, without a set of explicit demonstrations or a reward function, and achieving significantly better performance cooperatively with a human than a human performing the task alone.
1 Introduction
Many tasks that we would like our agents to perform, such as unloading a dishwasher, straightening a room, or restocking shelves are inherently user-specific, requiring information from the user in order to fully learn all the intricacies of the task. The traditional paradigm for agents to learn such tasks is through rewards and demonstrations. However, iterative reward engineering with untrained human users is impractical in real-world settings, while demonstrations are often burdensome to provide. In contrast, humans learn from a variety of interactive communicative behaviors, including nonverbal gestures and partial demonstrations, each with their own information capacity and effort. Can we enable agents to learn tasks from humans through such unstructured interaction, requiring minimal effort from the human user?
The effort required by the human user is affected by many aspects of the learning problem, including restrictions on when the agent is allowed to act and restrictions on the behavior space of either human or agent, such as limiting the user feedback to rewards or demonstrations.
We consider a setting where both the human and the agent are allowed to act throughout learning, which we refer to as interactive learning.
Unlike collecting a set of demonstrations before training, interactive learning allows the user to selectively act only when it deems the information is necessary and useful, reducing the user's effort.
Examples of such interactions include allowing user interventions, or agent requests, for demonstrations
To this end, we propose to allow the agent and the user to exchange information through an unstructured interface.
To do so, the agent and the user need a common prior understanding of the meaning of different unstructured interactions, along with the context of the space of tasks that the user cares about.
Indeed, when humans communicate tasks to each other, they come in with rich prior knowledge and common sense about what the other person may want and how they may communicate that, enabling them to communicate concepts effectively and efficiently
In this paper, we propose to allow the agent to acquire this prior knowledge through joint pre-training with another agent who knows the task and serves as a human surrogate. The agents are jointly trained on a variety of tasks, where actions and observations are restricted to the physical environment. Since the first agent is available to assist, but only the second agent is aware of the task, interactive learning behaviors should emerge to accomplish the task efficiently. We hypothesize that, by restricting the action and observation spaces to the physical environment, the emerged behaviors can transfer to learning from a human user. An added benefit of our framework is that, by training on a variety of tasks from the target task domain, much of the non-user specific task prior knowledge is pre-trained into the agent, further reducing the effort required by the user.
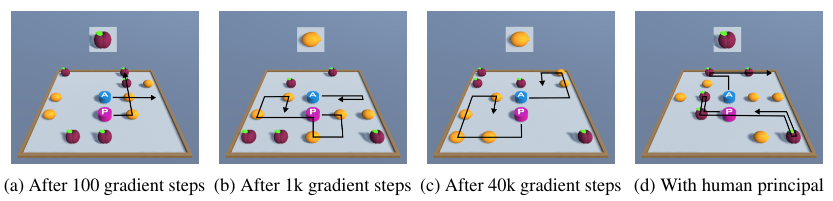
We evaluate various aspects of agents trained with our framework on several simulated object gathering task domains, including a domain with pixel observations, shown in Figure 1. We show that our trained agents exhibit emergent information-gathering behaviors in general and explicit question-asking behavior where appropriate. Further, we conduct a user study with trained agents, where the users score significantly higher with the agent than without the agent, which demonstrates that our approach can produce agents that can learn from and assist human users.
The key contribution of our work is a training framework that allows agents to quickly learn new tasks from humans through unstructured interactions, without an explicitly-provided reward function or demonstrations. Critically, our experiments demonstrate that agents trained with our framework generalize to learning test tasks from human users, demonstrating interactive learning with a human in the loop. In addition, we introduce a novel multi-agent model architecture for cooperative multi-agent training that exhibits improved training characteristics. Finally, our experiments on a series of object-gathering task domains illustrate a variety of emergent interactive learning behaviors and demonstrate that our method can scale to raw pixel observations.
2 Related Work
The traditional means of passing task information to an agent include specifying a reward function
Another recent line of research involves the human expressing their preference between agent generated trajectories
Our work builds upon the idea of meta-learning, or learning to learn
When a broader range of interactive behaviors is desired, prior works have introduced a multi-agent learning component
3 Preliminaries
In this section, we review the cooperative partially observable Markov game
The functions and are not accessible to the agents. At time , the environment accepts actions , samples , and returns reward and observations . The objective of the game is to choose actions to maximize the expected discounted sum of future rewards:
Note that, while the action and observation spaces vary for the agents, they share a common reward which leads to a cooperative task.
4 The LILA Training Framework
We now describe our training framework for producing an assisting agent that can learn a task interactively from a human user.
We define a task to be an instance of a cooperative partially observable Markov game as described in Section 3, with .
To enable the agent to solve such tasks, we train the agent,
whom we call the "assistant" (superscript ), jointly with another agent, whom we call the "principal" (superscript ) on a variety of tasks. Critically, the principal's observation function informs it of the task.
The principal agent acts as a human surrogate which allows us to replace it with a human once the training is finished.
By informing the principal of the current task
and withholding rewards and gradient updates until the end of each task, the agents are encouraged to emerge interactive learning behaviors in order to inform the assistant of the task and allow them to contribute to the joint reward.
We limit actions and observations to the physical environment, with the hope of emerging human-compatible behaviors.
Our tasks are similar to tasks in
In order to train the agents, we consider two different models. We first introduce a simple model that we find works well in tabular environments. Then, in order to scale our approach to pixel observations, we introduce a modification to the first model that we found was important in increasing the stability of learning.
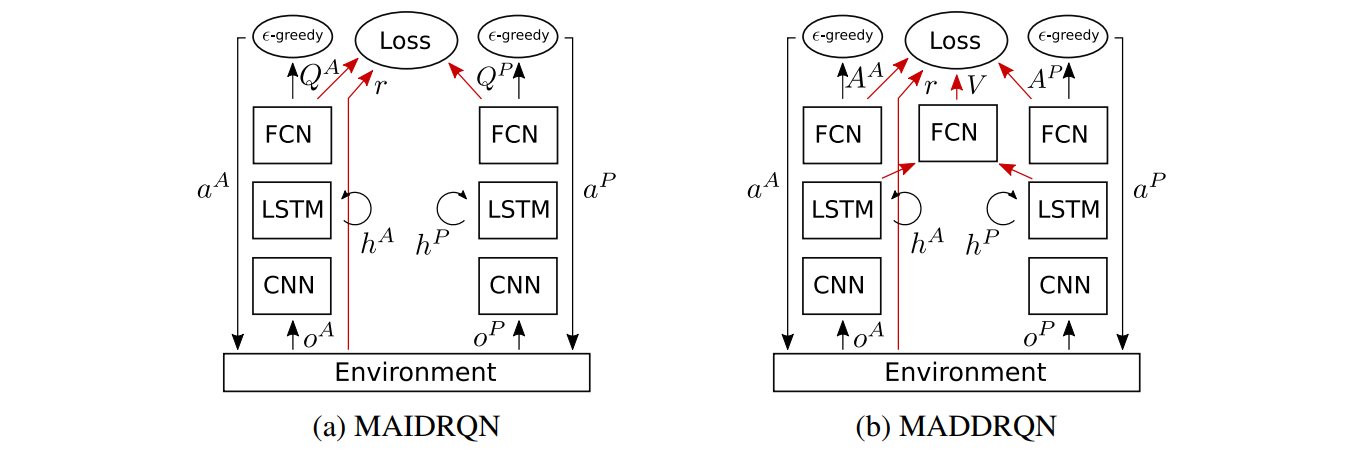
Multi-Agent Independent DRQN (MAIDRQN):
The first model uses two deep recurrent -networks (DRQN)
.
The networks are trained simultaneously on the same transitions, but do not share weights and gradient updates are made independently for each agent. The model architecture is a recurrent neural network, depicted in Figure 2a; see the paper for details. We use this model for experiments 1-3.
Multi-Agent Dueling DRQN (MADDRQN): With independent Q-Learning, as in MAIDRQN, the other agent's changing behavior and unknown actions make it difficult to estimate the Bellman target, in , which leads to instability in training. This model addresses part of the instability that is caused by unknown actions.
If is the optimal action-value function, then the optimal value function is , and the optimal advantage function is defined as
,
where is an advantage function for agent and is a joint value function.
The training loss for this model, assuming the use of per-agent recurrent networks, is:
,
where
.
Once trained, each agent selects their actions according to their advantage function , , as opposed to their Q-function in the case of MAIDDRQN.
In the loss for the MAIDRQN model, , there is a squared error term for each which depends on the joint reward . This means that, in addition to estimating the immediate reward due their own actions, each must estimate the immediate reward due to the actions of the other agents, without access to their actions or observations. By using a joint action value function and decomposing it into advantage functions and a value function, each can ignore the immediate reward due to the other agent, simplifying the optimization.
We refer to this model as a multi-agent dueling deep recurrent -network (MADDRQN), in reference to the single agent dueling network of
Training Procedure: We use a standard episodic training procedure, with the task changing on each episode. Here, we describe the training procedure for the MADDRQN model; the training procedure for the MAIDRQN model is similar, see Algorithm~\ref{alg:maidrqn} in the appendix for details. We assume access to a subset of tasks, , from a task domain, . First, we initialize the parameters , , and . Then, the following procedure is repeated until convergence. A batch of tasks are uniformely sampled from . For each task in the batch, a trajectory, , is collected by playing out an episode in an environment configured to , with actions chosen -greedy according to and . The hidden states for the recurrent LSTM cells are reset to at the start of each episode. The loss for each trajectory is calculated using . Finally, a gradient step is taken with respect to , , and on the sum of the episode losses. Algorithm~\ref{alg:maddrqn} in the appendix describes this training procedure in detail.
5 Experimental Results
We design a series of experiments in order to study how different interactive learning behaviors may emerge, to test whether our method can scale to pixel observations, and to evaluate the ability for the agents to transfer to a setting with a human user.
We conduct four experiments on grid-world environments, where the goal is to collect all objects from one of two object classes. Two agents, the prime and the assistant, act simultaneously and may move in one of the four cardinal directions or may choose not to move, giving five possible actions per agent.
Within an experiment, tasks vary by the placement of objects, and by the class of objects to collect, which we call the "target class". The target class is supplied to the principal as a two dimensional, one-hot vector. Each episode consists of a single task and lasts for 10 time-steps. Table 1 gives the setup for each experiment; see the paper for details.
We collected 10 training runs per experiment, and report the aggregated performance of the 10 trained agent pairs on 100 test tasks not seen during training. The training batch size was 100 episodes and the models were trained for 150,000 gradient steps (Experiments 1-3) or 40,000 gradient steps (Experiment 4).
Experiment 1 A&B - Learning and Assisting: In this experiment we explore if the assistant can be trained to learn and assist the principal. Figures 3 and 4 show the learning curve and trajectory traces for trained agents in Experiment 1B.
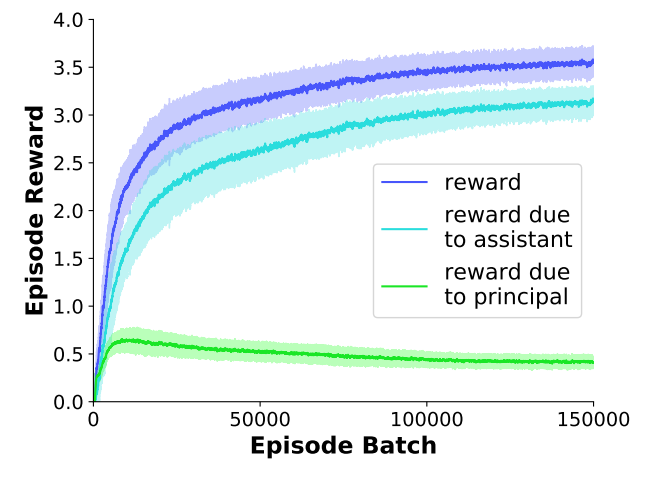
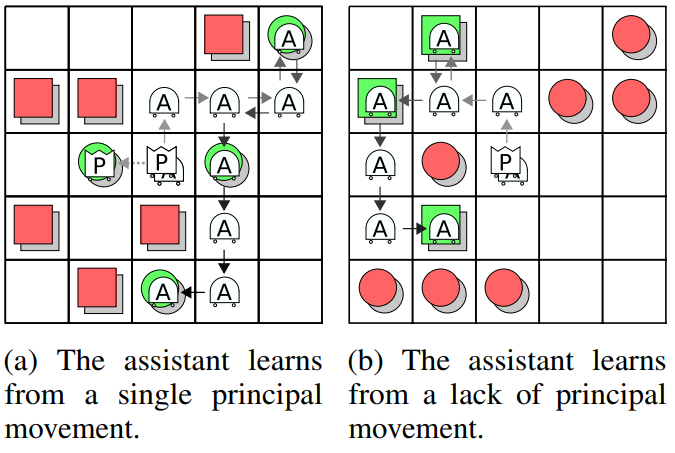
Table 2 shows the experimental results without and with a penalty for motion of the principal (Experiments 1A and 1B respectively).
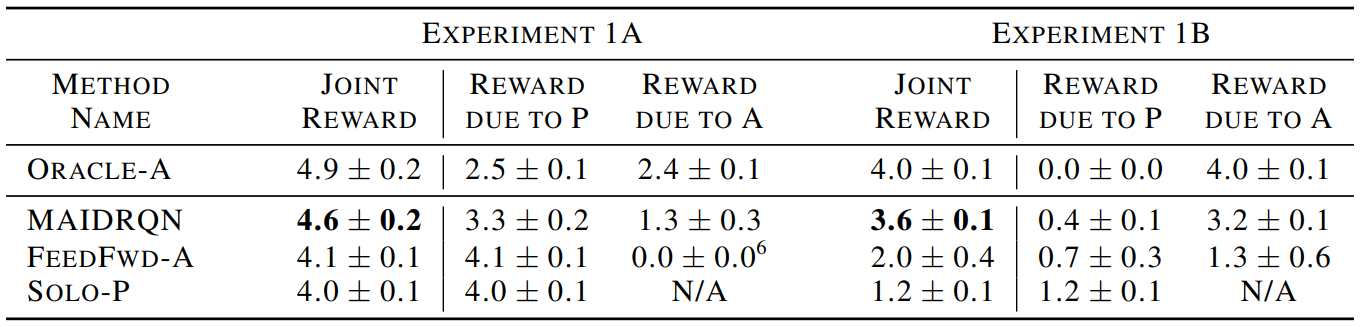
The joint reward of our approach (MAIDRQN) exceeds that of a principal trained to act alone (Solo-P), and approaches the optimal setting where the assistant also observes the target class (Oracle-A). Further, we see that the reward due to the assistant is positive, and even exceeds the reward due to the principal when the motion penalty is present (Experiment 1B). This demonstrates that the assistant learns the task from the principal and assists the principal. Our approach also outperforms an ablation in which the assistant's LSTM is replaced with a feed forward network (FeedForward-A), highlighting the importance of recurrence and memory.
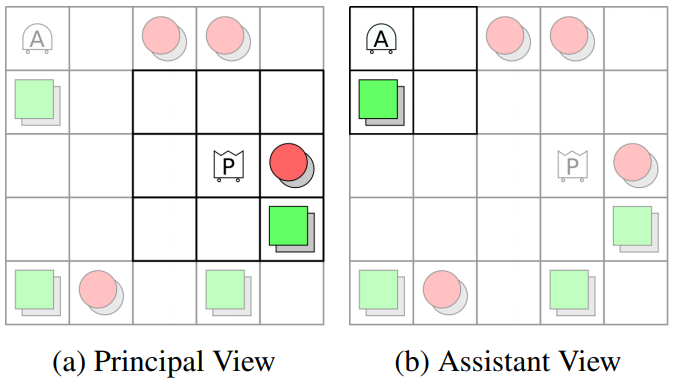
Experiment 2 - Active Information Gathering: In this experiment we explore if, in the presence of additional partial observability, the assistant will take actions to actively seek out information. This experiment restricts the view of each agent to a 1-cell window and only places objects around the exterior of the grid, requiring the assistant to move with the principal and observe its behavior, see Figure 5. Figure 6 shows trajectory traces for two test tasks. The average joint reward, reward due to the principal, and reward due to the assistant are , , and respectively. This shows that our training framework can produce information seeking behaviors.
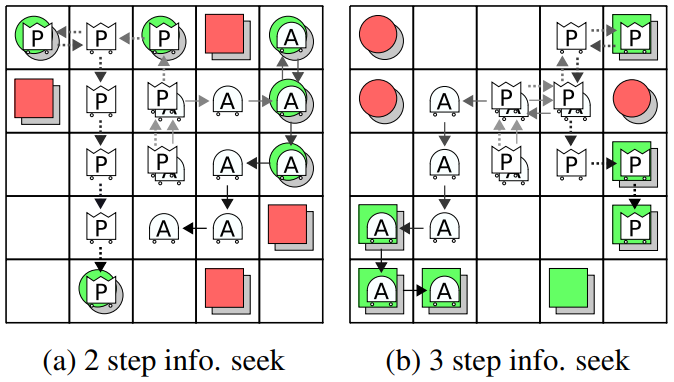
Experiment 3 - Interactive Questioning and Answering: In this experiment we explore if there is a setting where explicit questioning and answering can emerge. On 50% of the tasks, the assistant is allowed to observe the target class. This adds uncertainty for the principal, and discourages it from proactively informing the assistant. Figure 7 shows the first several states of tasks in which the assistant does not observe the target class. The test and training sets are the same in Experiment 3, since there are only 8 possible tasks.
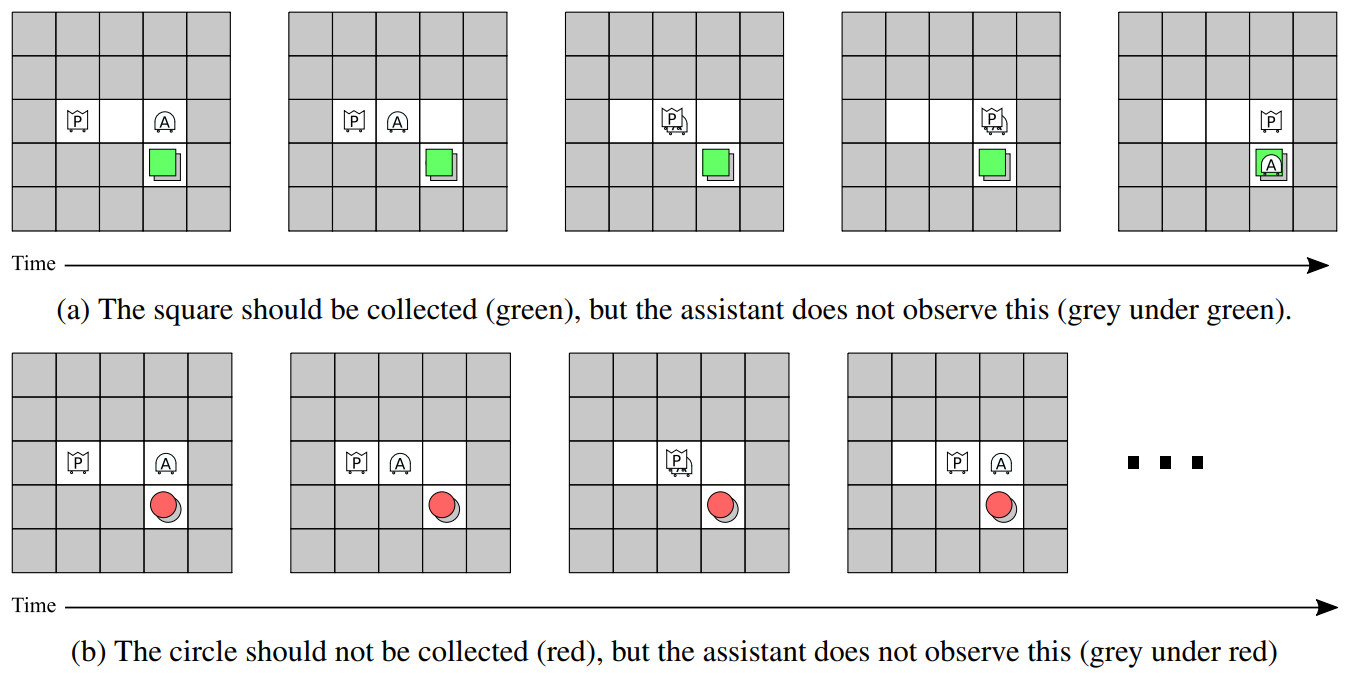
The emerged behavior is for the assistant to move into the visual field of the principal, effectively asking the question, then the principal moves until it sees the object, and finally answers the question by moving one step closer only if the object should be collected. The average joint reward, reward due to the principal, and reward due to the assistant are , , and respectively. This demonstrates that our framework can emerge question-answering, interactive behaviors.
Experiment 4 - Learning from and Assisting a Human Principal with Pixel Observations: In this final experiment we explore if our training framework can extend to pixel observations and whether the trained assistant can learn from a human principal. Figure 8 shows examples of the pixel observations.
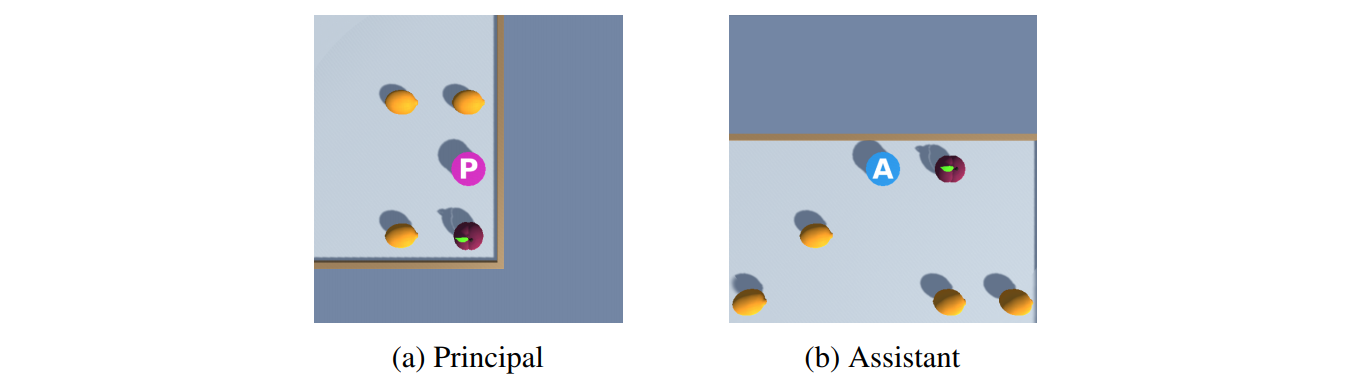
Ten participants, who were not familiar with this research, were paired with the 10 trained assistants, and "played" 20 games with the assistant and 20 games without the assistant. Participants were randomly assigned which setting to play first. Figure 1 shows trajectory traces on test tasks at several points during training and with a human principal after training. Table 3 shows the experimental results.

The participants scored significantly higher with the assistant than without (confidence>99%). This demonstrates that our framework can produce agents that can learn from humans.
Unlike the previous experiments, stability was a challenge in this problem setting; most training runs of MAIDRQN became unstable and dropped below 0.1 joint reward before the end of training. Hence, we chose to use the MADDRQN model because we found it to be more stable than MAIDRQN. The failure rate was 64% vs 75% for each method respectively, and the mean failure time was 5.6 hours vs 9.7 hours (confidence>99%), which saved training time and was a practical benefit.
6 Summary and Future Work
We introduced the LILA training framework, which trains an assistant to learn interactively from a knowledgeable principal through only physical actions and observations in the environment. LILA produces the assistant by jointly training it with a principal, who is made aware of the task through its observations, on a variety of tasks, and restricting the observation and action spaces to the physical environment. We further introduced the MADDRQN algorithm, in which the agents have individual advantage functions but share a value function during training. MADDRQN fails less frequently than MAIDRQN, which is a practical benefit when training. The experiments demonstrate that, depending on the environment, LILA emerges behaviors such as demonstrations, partial demonstrations, information seeking, and question answering. Experiment 4 demonstrated that LILA scales to environments with pixel observations, and, crucially, that LILA is able to produce agents that can learn from and assist humans.
A possible future extension involves training with populations of agents.
In our experiments, the agents sometimes emerged overly co-adapted behaviors. For example, in Experiment 2, the agents tend to always move in the same direction in the first time step, but the direction varies by the training run.
This makes agents paired across runs less compatible, and less likely to generalize to human principals.
We believe that training an assistant across populations of agents will reduce such co-adapted behaviors.
Finally, LILA's emergence of behaviors, means that the trained assistant can only learn from behaviors that emerged during training. Further research should seek to minimize these limitations, perhaps through advances in online meta-learning